
闲聊
最近感觉没有状态了,突然感觉很空虚,老是觉得自己很卑微,但一点干劲都榨不出来。
c++非常灵活,但是我学习的时候是课本是以 c++98标准的,emm,非常老了。现在使用 c++11甚至c++20 ,感觉98和11以及不是一种语言了,太大的差异。
我而且对标准库使用起来还是很不熟练,特别是容器之类的,今天起,就要步入到现代c++学习哇。
电子版查阅资料:
纸质版
Effeetive C++More Effeetive C++
最近刚好学习 串这个数据结构,关键是讲述kmp算法,
顺便练习一些c++,我就自己实现了string类,并且简单实现了部分功能。
实现起来还算顺利,顺便复习一下c++面对对象的知识点。
- 类 构造析构函数
- 重载以及重载符号
- 友元函数
- 等知识点
还遇到了一个小问题,
- 比如右值引用的问题
- 还学习到了一个小技巧,传入参数是类的对象时,函数执行的时候会调用析构函数和拷贝构造函数,如果该函数需要频繁的调用,无疑是增加了时间开销,我们可以传入引用,但是这个函数不具有在修改参数中的对象的功能,比如求两个串的比较,传入静态引用就好。
源码呢,大概有三四百行,放在github(点我访问)上了,现在觉得自己的代码风格还不是很完美,希望日后自己的代码不但简洁,而且还非常规范(逼格)。
认识串
计算机上处理最多的非数值的数据就是字符串了,比如信息检索程序、文字编辑程序、翻译程序等。字符串简称串,在计算机中表示数是非常简单的,计算机也这为数据计算而设计的,所以在处理非数值的字符串就显得要复杂一些。并且在不同的程序中、不同的语言中,不同的机器中,操作系统,编程语言.....,所处理的字符串具有不同的特点,所以我们要更具不同的环境选择合适的存储结构,不同算法。
串,本质上还是线性表,是存储类型收到限制(只能存储字符)的数据结构.串是由多个或者零个字符组成的有限序列。
为了方便后续描述,字符串记为 ==s = "a1a2a3.....an"==
初步了解
==s = "a1a2a3.....an"==
- s成为串名
- n成为串长
- 串长为0的字符串为空串
串中任意个连续的字符组成的串,叫该串的子串,包含该子串 的串也就被叫成 主串
字串在主串的位置,即为字串的首字母在 主串的位置
串被 " " 括起来,作为边界符,不作为 串的组成部分,这和c语言java是一致的.
注意: 由 空格 组成的串,叫做空格串, 要和空串区分开来.空格也是占位置的.
本篇,字符串的序号是从0开始计数的.
串的基本操作还是熟悉的增删改查,通常都是以字串为操作对象的.
串的数据对象限定为 字符集 ,关于字符集、字符编码等问题 ,我特意查询了许多材料,解答了我多年的困惑------字符编码问题
存储串,我现在掌握也就两大类,链式和顺序表。但是由于串的字节一些经常操作的特性,当然要特别考虑一些。
串的基本操作
StrAssign(&T,chars);chars是字符常量, 生成一个存储着chars的串TStrCopy(&T,S);将串S复制到 T中StrEmpty(S);判断 串S是否为空串StrCompare(S,T);比较S,T字符串StrLenth(S);获取 S串的长度ClearString(&S);清空串的长度Concat(&T,S1,S2);将串拼接到 S中SubString(&Sub,pos,len);求在pos位置起长度为 len的字串subIndex(S,T,pos);模式匹配,字串T在 主串S中的第pos起,再字串第几个位置Repalce(&S,T,V);使用串V替换主串中出现和T一样且不重叠的串。StrInsert(&S,pos,T);在第pos位置上插入串 T.StrDlete(&S,pos,len);删除串在pos位置上 长度为len的字串。DestroyString(&S);销毁串
由于串本质上就是线性表,所以线性表中的基本操作和串的基本操作有很大的重叠,我们这里止阐述 串的特有的操作 ,重点介绍模式匹配。
串的实现
实现串,无非就是链表和顺序表。 先暂时讨论ASCII字符集,一个中文字符使用GBK编码存储到char里,一个是不够的,需要两个char的空间。 建议使用 wchar_t 类型存储非英文字符。
使用定长的静态顺序表
#define MAXSTRLEN 255
typedef unsiged char SString[MAXSTRLNE + 1]//第0号位置存储着 字符串的长度
unsigned 在c语言就是无符号的(本质上就是 ,原码最高位1不代表是负数 ),这里修饰char,char在c语言占有一个字节,那么 unsiged char 可以表示整型数据的范围就是 0~255(28).
使用本定义方法,第0个位置不存储 字符(ASC码),存储着整个字符的长度。第零个位置只有一个字节的存储空间,所以最大正整数也只能是-27 ~ 27 ,但是我们定义的是无符号的char,所以为0~255(28)。
因为长度在串中经常使用,所以我们宁愿使用一个存储空间去存储长度。当然这里还可以其一个作用,定界,有了长度和起始地址,我们才可以确定该字符串的边界。
还有一个定界的方式,C语言中,在字符串的末尾加了 ASC码为 0的符号 \0,读取到这个符号,表明该串已经结束了。 使用这种方式,如果需要频繁获取字符串的长度,就需要一个 时间复杂为 O(n) 的大循环。
由于长度被限制死了,所以超出255的字符我们就截断不在保存。
使用堆内存存储(动态顺序表)
我们字符串往往长度都大于255,那么我们可以使用 malloc函数申请串长len长度的空间,等到串遇到插入,cat,等操作,可以动态的变化空间。
typedef struct {
char * ch;//如果为空串,ch为NULL
int length;
}HString;
以下都是课本上非常经典的算法,我这里摘抄一下
比较
StrCompare(HString S,HString T)
int StringCompare(Hstring S,Hstring T)
{
//如果S>T 则返回 >0 ;如果相等返回 0;如果S<T ,返回 <0
for(i=0;i<S.length&&i<T.length;i++)
if(S.ch[i]!=T.ch[i]) return S.ch[i] -T.ch[i];
return S.lenght-T.lenght;
}
别看这些语句没多少,但是考虑所有的情况。
比较字符串,无非就是比较各个字符的 ASCII 的大小。
这样我们应当考虑一下情况
- S,T等长 但是字符不一样,例如
S=''abb''T=''abc'' - S,T不等长 但是存在字串和主串的关系,例如
S=''abbbbb''T=''abb'' - S,T 等长 ,字串且一致
- 等等
for(i=0;i<S.length&&i<T.length;i++)
if(S.ch[i]!=T.ch[i]) return S.ch[i] -T.ch[i];
这一段代码,可以完美解决, 在两个字符串之一中没有遍历完,出现字符不一样的情况。S.ch[i] -T.ch[i]; , 使用差表示了ASCII的比较结果
return S.lenght-T.lenght;
这一句代码就是,考虑 3、2 的情况。
虽然代码不多,但是本算法非常经典。
求字串
SubString(HString &Sub,HString S,int pos,int len)
功能:求 S中在pos位置起,长度为len的字串,保存在 sub中。
这里隐含着一个条件len< S.length - pos ,如果在pos位置后长度不够len是无法求出长度为len的字串的。
status SubString(HString &Sub,HString S,int pos,int len)
{
if(pos<1||pos>S.length||len<0||len> S.length - pos)
return ERROR;
if(Sub.ch) free(ch); //清空原有串
if(!len) {Sub.ch=NULL;Sub.length=0} //如果len==0
else
{
Sub.ch=(char*)malloc(len*sizeof(char));
Sub.ch[0....len-1]=S.ch[Pos-1....Pos+len-2];
Sub.length=len;
}
return OK;
}
块链存储
采用链式存储,如果采用一个字符存在一个结点中,这里就存在一个问题,本来存储一个字符就要一个字节,但是这样存一个字符还要多花一个指针的空间(4字节或者8字节) ,存储密度变了成1/5,实在是得不偿失。
所有我们这里采用块链的形式,简单就是,一个结点不仅仅存储一个字符,存储一组数目确定的字符
#define CHUNKSIZE 80 //每一块的大小
typedef struch Chunk
{
char ch[CHunKSize];
struck Chunk * next;
}Chunk;
typedef stuck
{
Chunk *head,*tail;//串头 串尾
int curlen;//当前串的长度
}
当然这样遇到了一个新的问题,如果一个块存储空间没有使用完,但是一部分字符存储其他块中,这要就使用特殊的字符占用此空间表示,不属于本字符串。
模式匹配
模式匹配是本章中一个非常重要的算法。我们这里介绍两种算法,穷举法和KMP算法。当然KMP会难一点,但是通过ta我们会得到很多启发。
模式匹配我们要经常使用,比如文档里的查找? 搜索引擎的搜索?
基本概念
模式匹配即为前面Index(S,T,pos); 函数。
S 叫 主串,匹配的字串T 叫做模式串,本函数就是求得模式串在主串中的位置,故而叫做 模式匹配。
我们这里以主串
a b a b c a b c a c b a d 模式串
abcac作为例子讲解
采用的静定长的顺序表存储
穷举法
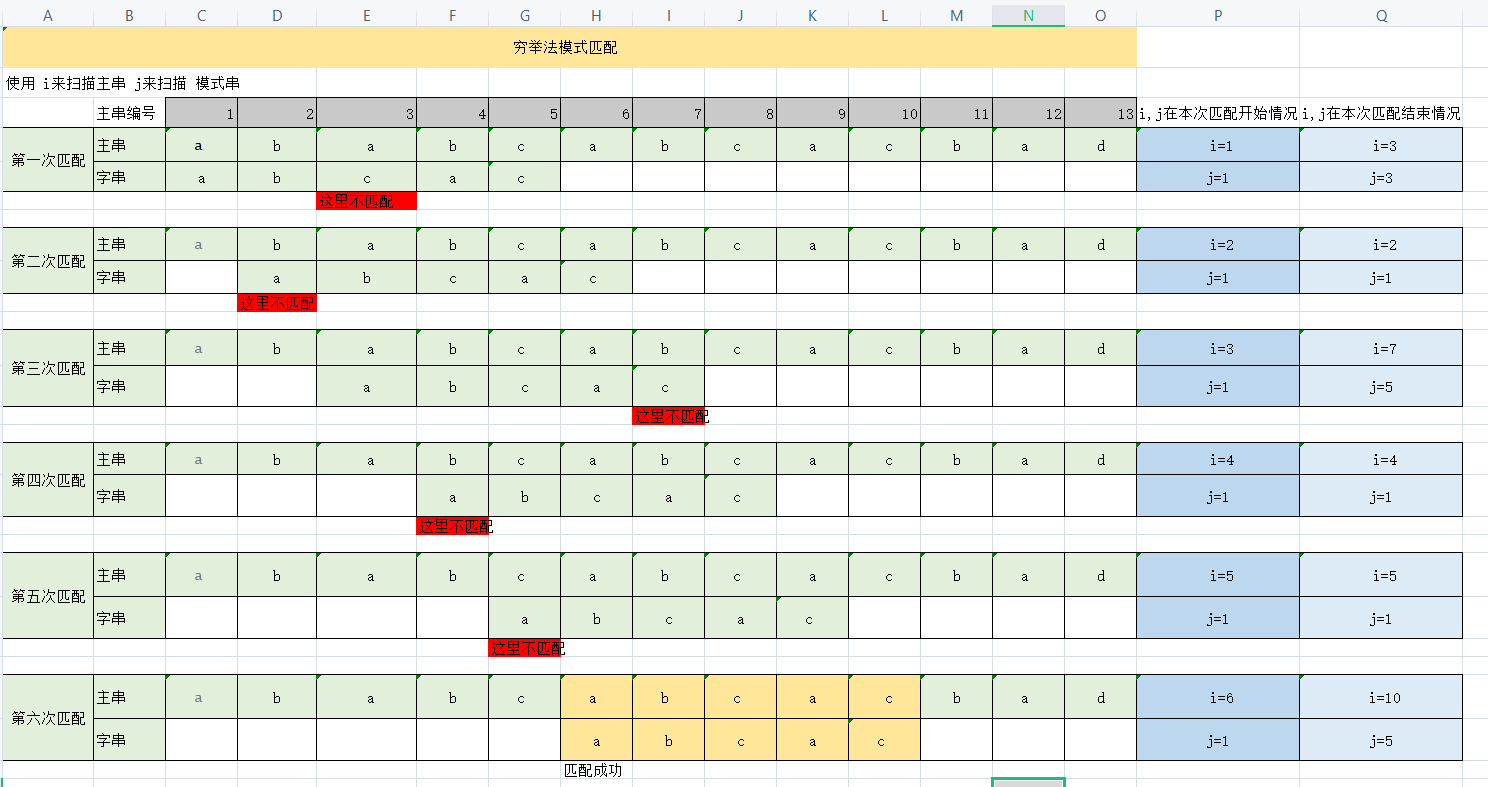
穷举法 思路: 从主串的第一个字符开始 取 len长度的子串和模式串做比较,直到 取得的子串和模式串完全匹配为止。
如上图,使用 i来扫描主串 j来扫描 模式串,再取得子串之后 i++,j++ 分别开始对比字符是否一样。如果匹配失败,i回到 上次取子串的位置上,j回到模式串的1号位,然后再次取字符串直到下一次匹配成功。
我们来看一下代码实现:
int Index(SString S,SString T,int pos)
{
i=pos;j=1;
while(i<=S[0]&&j<=T[0])
{
if(S[i++]==T[j++]);//如果相等 查看 下一个字符是否也匹配
else{i=i-j+2;j=1;} //i回溯到上一次取子串的下一个位置
}
if(j>T[0]) return i-T[0];
else return 0;
}
先解释一些较难的语句
while(i<=S[0]&&j<=T[0]) 这里是循环的出口 ,当i=S[0](S[0] 存着 S串的长度)是 主串已经遍历完毕;j=T[0] 说明子串遍历到了最后一个字符,说明匹配成功。
if(S[i++]==T[j++]); 这样看就简答多了 if(S[i]==T[j)i++;j++;
i=i-j+2; 这里就是 让i回到上一个位置, 讲起拆开来看,i=i-j+1 +1;
- i-j+1 是让i回到 取子串的位置
- 再+1 是为了向下一个遍历位置移动。
这种方法,可以做到到100%不漏掉一个可能。但是是否可以优化呢?我们先看一个时间复杂度 设主串长度位n ,模式串长度为 m。最坏时间情况下 ,需要对比 (n-m+1)*m次
- n-m+1 主串可以取得的子串个数
- m 模式串多长 就意味着要对比多少次
这里是否存在 ,多余的对比呢?
比如第二次匹配就多余了!
倘若主串是aaaaaab ,而子串是 ab,虽然我们可以一眼的定位到最后位置,但是穷举法却实诚地一个一个对比。
KMP 算法
KMP算法是对穷举法的优化,我们再穷举法里回溯 i,但是在 KMP算法中,我们可以不回溯i ? 这是如何做到的呢?
人脑的思考
加入你是计算机,你会像穷举法一样取匹配吗? 我来猜测一些你的思路 大概如下图一样,三次对比就ok!

我们在第一次匹配失败之后,并没有将 将i指向 第2个位置 ,而是 原地不动, 因为我们的直觉告诉我们,因为在第2个位置取子串一定会和 模式串不同,因为开头字母都不一样嘛。
在第二次匹配失败的时候,我们也没有回溯i ,因为我们直到 在 4,5位置上取子串,一定不同,为啥?还是因为 开头字母都不一样嘛,但是!第六个位置上是否确定呢? 我们这里说好的不回溯i ,但是我们又想回溯。
这里可以做一个等价的操作,让模式串从第二个开始比,也就说j回溯到第2号元素,相当于我们默认比对了 主串第6个位置和模式串第1个位置。
这里重点关注第三次循环,我们为啥有底气让j回溯到2,却不会漏掉情况呢?
底气就是在第2次匹配中,模式串 匹配的失败的地方c前面是a ,在主串中和c匹配失败的字符的前一个字符一定是a。
我们再往深处想一点,是不是 只要再c处匹配失败,那么此时匹配失败的前一个字符一定是a,那么j应该回溯到第 2 个位置。
那么再提一个问题,j在c处匹配失败回溯到第二个位置是否与主串有关? 答案是无关的,从上一句话可得出,回溯到第二个的原因,完全是模式串 c前面的字符和 第二个前面的字符一样。
根据前面的推理我们可以做以下猜测
- 我们可以不回溯 i, 只回溯j,但是回溯j要做特殊处理
- 模式串匹配的失败的地方,对于的j要回溯的地方和 主串无关
- 模式串匹配失败的地方,前面的字符(或串)要和模式串的从第一个位置起(包含第一个字符)的串 一样。
虽然有点绕口,但是我们可以实战一下,假设模式串是 aabaab 我们一次来判断每一个位置匹配失败之后 j要回溯到哪个位置上?
-
第一个位置匹配失败,当然j要回溯到 第一个位置
j=1 -
第二个位置匹配失败 , j也只能回溯到第一个位置,如果回到第二个位置?不是刚匹配过吗?再对比有啥意义呢?
j=1
-
第三个位置匹配失败,说明此时匹配失败的地方?以前一个字符的字符一定是 a
所以
j=2即可,检查此时的?是不是 a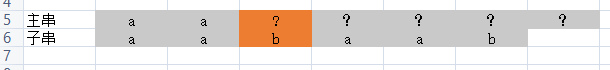
-
再第四个位置上匹配失败 ,说明 主串?之前的位置一定是b,此时j应该回溯到
j=1检查?是不是a. 但是这里发现a和?匹配失败,说明此时 这个? 一定不是 a ,我们还需要 让 j=1 再去对比吗,不需要了。这里就说明本算法还有优化的空间,这我们后续再说!
-
j=2,和前面的推理一样 -
j=3,和前面的推理一样
我们将 j将回溯到哪里存在一个数组了 next[6] (next下表从1开始推算)={1,1,2,1,2,3};并且next数组和主串无关, 我们可以涉及一个算法来推算处next数组,直到了next数组再去模式匹配,岂不是快很多?

数学证明
假设主串是 S="s1s2s3s4s...."
模式串是 T="p1p2p3p4p...."
在模式串中第j处匹配失败,应该让j回溯到 第k个位置上
说明: 主串匹配失败的i位置起 前k-1个字符 和 模式串 从头算起 k-1个字符 组成的串一样
即为si-ks......si-4si-3si-2si-1 = p1p2p....pi+k-1
我们还可以得出,在模式串匹配失败的地方j起k-1个字符组成的串和 主串匹配失败的i位置起 前k-1个字符组成的串一样
即为si-ks......si-4si-3si-2si-1 = pj-k+1p...pj-2pj-1
两个式子连立,我们可以得出 p1p2p....pk-1=pj-k+1p...pj-2pj-1 (前缀等于后缀)
从这个式子中我们可以得出 一个结论!
使用结论口算 next
先直到两个概念:
串的前缀:必须包含第一个字符,但是不能包含最后一个字符的子串
串的后缀:必须包含最后一个字符,但是不能包含第一个字符
规定长度为1的模式串,没有前缀和后缀!
那么next[j-1]等于 在模式串第j个位置向前截断(不包含第j个字符)的子串T,T的前缀和后缀的最大可能重复数+1。
举一个例子,例如 求aabaab 第 3个位置的next[3] 。
前缀 为a ,后缀也为 a,那么最大重合数=1,再+1 =2 ,所以next[3] =2;
那么第6位置呢?
前缀可以取 aa ,后缀可取 aa,此时重合数最大 ,所以a[6]=2+1=3;
所以 next[6] (next下表从1开始推算)={1,1,2,1,2,3};
这里为啥叫 next下表从1开始推算 ,第一 考试都是从1开始的,第二由于我们采用的是定长的顺序表,逻辑顺序是从1开始的。
这里我们做一个特殊处理 ,让 next[1]=0,这是为了方面我们后面处理,放到后面说。

再告诉一个小技巧: next[2]一定等于1
kmp 代码
int Index(SString S,SString T,int pos)
{
i=pos;j=1;
while(i<S[0]&&j<T[0])
{
if(j==0||S[i]==T[i])
{
i++;j++;//开始对比下一个字符
}else j=next[j];// 回溯 j到 next[j] 位置上
}
if(j>T[0]) return i-T[0];
else return 0;
}
其实和穷举法差不多,但是这里使用了事先求好的next数组
关键代码解析
if(j==0||S[i]==T[i]) 这里就得说明为啥 next[1]=0 了
我们回顾一下前面,什么时候 让 i++,j++(也就是对比下一个字符的时候)
- 当此时对比字符一样的时候,看看下一个字符是否一样
- j回溯到模式串第一个字符的时候,并且主串与模式串第一个字符都不匹配
- j回溯到模式串第一个字符的时候,并且主串与模式串第一个字符匹配
其实第2个第3个可以合起来说,这里我就想强调 只要j回溯到模式串第一个字符的时候,就要 i++,和j++
这里巧妙的时候,只要i+ + 和 j+ +之后 ,j就等于1,再else语句中也没有可能取到 next[0]
总结一句 next[1]=0 是为了标记 现在 j回溯到 模式串第一个字符了
如何求得 next数组
前面口算的方法,实现起来比较麻烦,我们这里使用递推的方法,
已知条件 next[1]=0 ,假设 next[j]=k ,我们现在欲求 next[j+1]
next[j]=k,就意味着,模式串j处字符前k个字符与模式串从第一个字符起,有k个字符一样且顺序相同。 求next[j+1],我们其实在求解j+1处有多少字符和模式串从第一个字符起,字符一样且顺序相同。
next[j]=k说明, p1p2p....pk-1=pj-k+1p...pj-2pj-1 (前缀等于后缀),这是我们前面推到处的公式哇
如果 pk = =pj ,X : 如下j=5这种情况
在第5位置上前缀和后缀有重复 ,即为 前缀a 后缀 a,pk =pj ,那么在j=6的位置上, 此时前缀和后缀还可以扩展1个, 前缀 aa 后缀 aa
使用数学表达式 :p1p2p....pk=pj-k+1p...pj-2pj-1 pj
那么可以得出结论 next[j+1]=next[k]+1
那么如果 pk !=pj 呢 , pk !=pj ,说明j+1处不能和前面一样,让前缀和后缀扩展1一个字符(j处的字符)。那么该如何求解呢
答案是回溯j,嗯,这里其实就是对模式串做模式匹配。还有疑问? next[j]=k ,就意味着,模式串j处字符前k个字符与模式串从第一个字符起,有k个字符一样且顺序相同。 回溯j,就是减少判断前缀和后缀串长度,取串长next[j]+1,不行,取串长next[next[j]]+1长度.....,直到前缀和后缀只能取第一个字符
我们回顾一下,S[i]!=T[i]时,我们执行的语句时为?----j=next[j]; 回溯j
如果 pk1 =pj 说明j+1处的取后缀 和 k1处取前缀相等。
p1p2p....pk=pj-k1+1p...pj-2pj-1 pj
则 next[j+1]= next[k]+1
其实这里就是在求 j+1处所组成的后缀子串最大和模式串第一个位置的前缀子串的最大重合字符数。
如果还pk1 !=pj 呢 很简单, 继续向前退一个 重复前面的过程,直到 next[k]=next[1]=0 此时 next[j+1]=1
代码实现
void get_next(SString T,int next[])
{
//next保存再 next中
i=1;next[1]=0;
while(i<T[0])
{
if(j==0||T[i]==T[j])
{
i++;j++;next[i]=j;
}else
j=next[j];
}
}
这些代码非常精炼,看了好久才明白。
重点代码解析
算法我们已经理解透彻了,但是能做到课本上如此精炼,还是非常难的。以下分析代码对应前面推理的语句。
i++;j++;
注意 j是从0开始计数的, j 比i小于1, 且执行这个语句之前时,又因为j==next[j], 那么j++ 就是 next[j+1]=next[j] +1;
2. next[i]=j;
- 当i==j时 ,相当于 在执行前面推理的
next[j+1]=next[j]+1; - 当i!=j时 ,相当于 在执行前面推理的
next[j+1]=next[k]+1;
j=next[j];这就是前面 取k1=next[k] 过程 ,即next[netx[j]]。
优化next数组
在前面一点,提到了,当然kmp算法还可以优化,
例如 aaaab 我们求出的next数组为{0,1,2,3,4}
假如在模式串第3位置 ,匹配失败,主串与之对应字符必定不是2, 那么j=2 ,我们在和第2个字符比较,100%匹配失败,最后在和才第一个字符比较。所有多比较了一次j=2
如果再第四个呢,就多了 2次 ....
优化也简单,只要来个判断就好了,如果 T[k]==T[j] ,那么next[i]=next[k];
代码实现
void get_next(SString T,int next[])
{
//next保存再 next中
i=1;next[1]=0;
while(i<T[0])
{
if(j==0||T[i]==T[j])
{
i++;j++;
if(T[i]!=T[j]) next[i]=j;
else next[i]=next[j];
}else
j=next[j];
}
}
结语
终于写完了 ,一共6352词。感觉后面描述 求解next推到不是很好,emm,现在太晚了,后续修改吧。
关于完整代码,在这里github(点我访问)


