
DOM
DOM(Document Object Model——文档对象模型)是用来呈现以及与任意 HTML 或 XML文档交互的API。DOM 是载入到浏览器中的文档模型,以节点树的形式来表现文档,每个节点代表文档的构成部分(例如:页面元素、字符串或注释等等)。
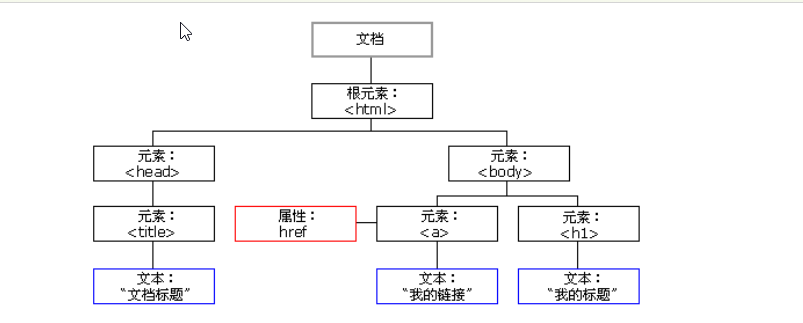
DOM树
-
文档(document): 一个页面就是一个文档 。
-
元素(element):所有的标签就是元素 ,
<html>是根元素。 -
节点(node):网页中所有的内容都可以叫做节点(标签,属性,文本,注释等)
获取元素
根据ID获取 getElementById()
getElementById()返回一个匹配特定 ID的元素对象,找不到返回null. 由于元素的 ID 在大部分情况下要求是独一无二的,这个方法自然而然地成为了一个高效查找特定元素的方法。
注意:
文档自上往下加载,获取的元素一定在前面是存在的,所以我们js代码应该写到元素的后面.
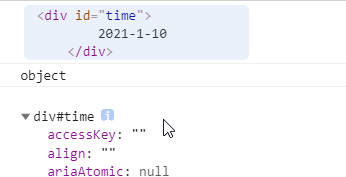
<div id="time">
2021-1-10
</div>
<script>
var timer = document.getElementById('time');//id要被引号圈起来.
console.log(timer);
console.log(typeof timer);//返回object类型
console.dir(timer);//查看方法和属性
</script>
根据标签名获取 getElementsByTagName
getElementsByTagName 返回带有指定标签名的对象的集合
- 对象的集合用伪数组存着,获取每一个元素则需要for遍历
- 得到的元素是动态的(这意味着它会随着DOM树的变化自动更新自身)
- 当只有一个标签复合的时候,返回的伪数组存着一个标签
- 没有元素复合要求返回的是一个空的伪数组
- 我们不仅可以获取document下的标签,我们还可指定标签获取
element. getElementsByTagName('<标签名>');,获取父标签下的子标签,
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
<ol>
<li>1+</li>
<li>2+</li>
<li>3+</li>
<li>4+</li>
<li>5+</li>
</ol>
<script>
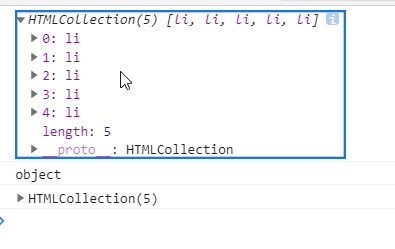
var lis = document.getElementsByTagName('li');//引号!!!
console.log(lis);
console.log(typeof lis);
console.dir(lis);
var ol = document.getElementsByTagName('ol');
var oli = ol[0].getElementsByTagName('li');//通过元素获取
console.log(oli);
</script>
根据类名获取getElementsByClassName(H5特有)
包含了所有拥有指定 class 的子元素。当在 document 对象上调用此方法时,会检索整个文档,包括根元素。由于多个标签可以用一个类名,所以获取还是一个伪数组存着
<nav class="nav">导航栏</nav>
<div class="nav">导航栏</div>
<script>
var nav = document.getElementsByClassName('nav');
console.log(nav);
</script>
可以指定选择器的querySelector(All)选择器(H5特有)
querySelector指定的选择器组匹配的元素的后代的**第一个元素**。.类选择器#id选择器 `啥都不加 标签选择器
-
返回一个
-
返回第一个
-
可以指定选择器
<nav class="nav">导航栏</nav>
<div class="nav">导航栏</div>
<script>
var nav = document.querySelector('.nav');
console.log(nav);
</script>
querySelectorAll返回指定选择器的元素对象的集合
- 返回集合
- 用伪元素存着
获取特殊的元素
-
获取body
var bodyEle=document.body; -
获取html
获取html和body不一样,不能document.html
var htmlEle = document.documentElement;
放假咸鱼的第16天

