
双链表
前面学习的单链表只有一个指向后驱节点的指针,带来的有一个麻烦——无法逆向检索。双链表有两个指针,一个指向后驱节点,一个指向前驱节点,所以双链表可进可退,但是存储密度会下降一丢丢。
定义
typedef struct DNode
{
ElemType data;
struct DNode *prior, *next;
} DNode, *DLinkList;
和单链表不同的就是,多了一个*prior。
初始化双链表和判断是否为空
双链表当然也有带头节点,和不带头节点的情况,我们只分析带头节点的。
bool InitDLinkList(DLinklist &L)
{
L = (DNode *)malloc(sizeof(DNode));
if (L == NULL)
return false;
L->prior = NULL; //带头节点的情况,头节点的prior永远指向 NULL
L->next = NULL;
return true;
}
判断是否为空十分接单,只需要判断L->next 是否为NULL即可。
bool Empty(DLinklist L)
{
if (L->next == NULL)
return true;
return false;
}
向后插入元素
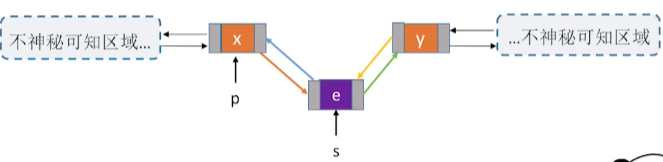
为了p后面插入插入元素s,我们需要执行如下步骤
- s的后驱指针p的后驱,
- p->next-prior 指向 s。
- 将 p节点的后驱指针指向 s ,
- s的前驱指针指向 p
注意语句顺序
但是这样操作有一个错误,如果 p就是最后一个元素,那么 p->next=NULL,第2步就无法执行
所以我们要单独拿出来说,没有后续节点就无需执行的第2步。
// 后插操作
bool InsertNextDNode(DNode *p, DNode *s)
{
if (p == NULL || s == NULL)
return false; //异常输入
s->next = p->next;
if (p->next != NULL)
p->next->prior = s;
s->prior = p;
p->next = s;
return true;
}
前向插入元素
我们其实无需再写一个那么多复杂代码,我们可以调用向后插入。
所谓前插元素就是 在当前元素的前一个元素进行后插操作,当然我们 这是带头指针的情况。
bool InsertPriorDNode(DNode *p, DNode *s)
{
if (p == NULL || s == NULL)
return false; //异常输入
return InsertNextDNode(p->prior, s);
}
删除后继节点q
这里和插入节点的步骤差不多
- 将 p的后驱指针指向 q->next;
- 判断q是否为最后一个元素,也就是,q.next==NULL?
- 如果不是 q->next->prior 指向 p
- 释放 q
- 删除成功
bool DeleteNextDNode(DNode *p)
{
if (p == NULL)
return false;
DNode *q = p->next;
if (q == NULL)
return false;
p->next = q->next;
if (q->next != NULL)
q->next->prior = p;
free(q);
return true;
}
销毁双链表
销毁双链表其实很简单,我们只需要调用前面删除后继节点函数即可。
- 从L->next;头元素开始删除,直到 L->next=NULL;
- 释放L
- L指向NULL
- 完成
bool DestoryList(DLinklist &L)
{
while (L->next != NULL)
DeleteNextDNode(L);
free(L);
L = NULL;
return false;
}
遍历节点
后向便利
DNode* p=L.next;
while(p!=NULL)
{
//要实现的操作
p=p.next;
}
前项遍历
DNode* p=<某一个节点>;
while(p->prior!=NULL)//不处理头节点
{
//要实现的操作
p=p.prior;
}
其实按位查找,按值查找都是通过此方法来实现的。
由于链表不具有随机存取的特性,所以查找的时间复杂度为O(n)
循环链表
循环链表有两种,一种是 单链表,另一种就是双链表了。
循环单链表
表尾的next指针指回来了 头节点 L
typedef struct LNode
{
int data;
struct LNode *next;
} LNode, *LinkList;

初始化和判断是否为空
// 初始化
bool InitList(LinkList &L)
{
L = (LNode *)malloc(sizeof(LNode));
if (L = NULL)
return false;
L->next = L; //头节点指向L
return true;
}
// 判断是否为空
bool Empty(LinkList L)
{
if (L->next == L)
return true;
return false;
}
我们从这里就可以看出循环链表的好处
- 头指针指向 表尾
- 尾指针指向 头指针
那么如果遍历的话,找到表尾就只需要 L->next;找到表头只需要L->next->next;时间复杂度 为 O(1)
相对于单链表,找到表尾需要O(n)的时间复杂度(while 遍历)。
我们许多操作都是在表头或者表尾进行操作的,所以这简化的许多操作。
注意: 当然我们要修改删除插入表尾结点,需要修改L的指向。
循环双链表
和双链表一样,有两个指针,表头结点的prior指向表尾,表尾结点next指向头节点,妥妥的双循环。
typedef struct DNode
{
int data;
struct DNode *prior, *next;
} DNode, *DLinkList;
初始化和判空
// 初始化
bool InitDLinkList(DLinkList &L)
{
L = (DNode *)malloc(sizeof(DNode));
L->next = L;
L->prior = L;
return true;
}
bool Empty(DLinkList L)
{
if (L->next == NULL)
return true;
return false;
}
向后插入和删除
当时循环链表的时候,我们插入和删除就无需考虑表尾指针next指向NULL了,所以代码也简化了不少。
bool InsertNextDNode(DNode *p, DNode *s)
{
if (p == NULL || s == NULL)
return false; //异常输入
s->next = p->next;
p->next->prior = s;
s->prior = p;
p->next = s;
return true;
}
删除同理
小小总结
每次代码逻辑容易出错的地方就是表尾和表头的这类边界问题,所以我们写代码的时候要着重考虑。
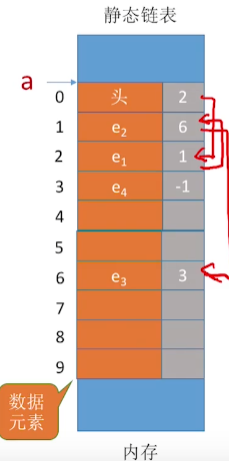
静态链表
单链表:数据分散在内存的各个角落中,
静态链表:分配一整个连续内存空间每个节点,每个节点集中安置;静态链表中没有了指针,但是数组的索引值 Index充当了指针的作用。
到这里,你可能会问顺序表和静态链表有啥区别?别急哈。
之仔细观察上图,下图 橙色的地方是数据域,灰色就是指针域,只不过数字就充当了指针。
静态链表,链字非常重要, 静态链表可以看做出单链表的简化版,或者看成一个逻辑存储顺序和物理存储顺序不一样的数组。
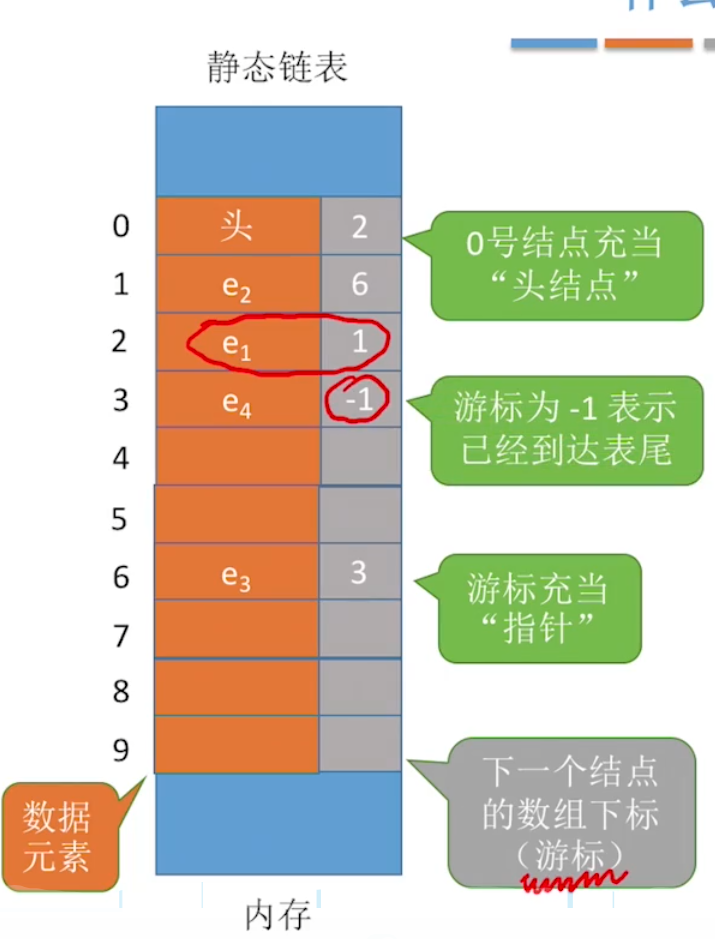
#define MaxSize 10
typedef struct Node
{
int data;
int next;//下一个节点的游标
} SLinkList[MaxSize];
这里分析一下 typedef 的用法。
基本语法: typedef <数据类型> <别名> 。
数据类型就是 struct Node{xxxx}[MaxSize]; 别名呢 SLinkList,感觉这样命名实在太复杂,
但是这样传达的意思十分明确,在声明 SLinkList a;的时候,就在强调a是静态链表。
SLinkList a ;<=> struct Node{xxxx} a[MaxSize];
验证一下哈,
初始化
初始化,就干三个事情
- 分配空间大小,
- 头指针指向分配的空间
- 头节点next指向NULL;
其中前面两件事情,定义的时候就完成了,那么就差第三步
指向NULL? 索引值可没有NULL,咋办呢?
其实可以认为 -1 就是 NULL.
void InitSList(SLinkList &L)
{
for (int i = 0; i < MaxSize; i++)
L[i].next = MaxSize;
L[0].next = -1;
}
这里我为了防止有脏数据,就把所有的next都初始化为 MaxSize 表示数据为空,-1表示表尾;
判空
其实非常简单了 ,直接判断 L[0].next==-1?
向后插入e
和单链表按位插入元素一样的
- 从头节点找到为序为 i-1第个结点,
- 找到一个空的新节点,填入数据e,
- 修改新的结点的next 为 i-i节点 的next
- 修改i-1节点的 next为 e的next
- 完成
当然,这里防止未来的我搞晕,强调一点:静态链表一个逻辑存储顺序和物理存储顺序不一样的数组。next就是数组的索引值。
#include <stdio.h>
#include <stdlib.h>
#define MaxSize 10
typedef struct Node
{
int data;
int next;
} SLinkList[MaxSize];
void InitSList(SLinkList &L)
{
for (int i = 0; i < MaxSize; i++)
L[i].next = MaxSize;
L[0].next = -1;
}
bool InsertNext(SLinkList &L, int e, int i)
{
if (i < 1)
return false;
// 找到i-1个元素p
int p = 0; //当前遍历到的节点index
int j = 0; //当前遍历到第j个节点
while (p != -1 && j < i - 1) //p == -1 是表明表尾
{
p = L[j].next;
j++;
}
if (p == -1) //如果插入的位置大于当前长度
return false;
// 找到空缺位置,填入数据 e,带头指针情况
int n = 1; //插入元素的index
while (n < MaxSize)
{
if (L[n].next == MaxSize)
{
L[n].data = e;
break;
}
n++;
}
// 如果空间不够失败
if (n == MaxSize)
return false;
L[n].next = L[p].next;
L[p].next = n;
return true;
}
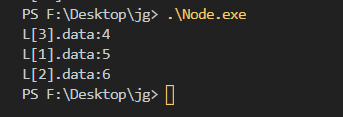
感觉有点不确定 验证一下
void printList(SLinkList L)
{
int p = L[p].next;
while (p != -1)
{
printf("L[%d].data:%d\n", p, L[p].data);
p = L[p].next;
}
}
int main()
{
SLinkList L;
InitSList(L);
InsertNext(L, 5, 1);
InsertNext(L, 6, 2);
InsertNext(L, 4, 1);
printList(L);
return 0;
}
按元素查找
其实这个和前面的差不多,考的还是如何遍历所有元素:
p=L[0].next;
while(p!=-1)//不是表尾
{
//操作
}
删除数据
和插入差不多
- 从头结点触发找到前驱结点(第i-1个)
- 修改前驱结点的next
- 删除结点的next值为MaxSize
代码实现略
静态链表的优点
增删改不需要移动大量元素,相对于顺序表
静态链表的缺点:
- 容量固定不变
- 无法随机读取
- 只能从头开始往后查
适用场景
- 不支持 指针的编程语言
- 数据元素固定不变的场景 如 文件分配表 FAT,用来记录文件所在位置的表格
第二章总结 :顺序表VS链表
无论是顺序表还是链表 在逻辑上看都是 线性结构
顺序表
优点: 支持随机存取,存储密度高
缺点:要求连续的存储空间,改变容量不方便,插入删除不方便
链式存储
优点: 存储空间离散,改变容量方便
缺点: 不可随机读取,存储密度低
基本操作
创 销 增删改查
这些操作离不开 遍历和插入操作。
顺序表 创建和删除销毁 插入
静态分配:系统为我们分配和销毁空间
动态分配:手动分配,需要手动销毁
插入和删除需要移动后续元素,平均时间复杂度为O(n),主要来自于移动元素
链表 创建和删除销毁
手动分配空间,销毁需要逐个结点free
插入删除元素只需要修改指针即可。
平均时间复杂度也为O(n),主要来自与遍历到目标元素
顺序表查找
时间复杂度:按位查找 O(1),按元素查找为 O(n),如果有序还可提升至O(log2n)
链表 查找
按位按值都是 O(n)
使用哪一个?
表长难以估计,经常增删数据----链表
表长可估计,查询(搜索)操作比较多----顺序表
第二章结束 _

