
内敛汇编
我们可以C++语言嵌入汇编,这里需要
int a=10;
__asm{
mov EAX ,a
}
补充
- 汇编语言不区分大小写
- 我在学习的时候使用的x86调试环境,如果换成x64的话汇编代码是不一样的。
- 当然我们使用debug模式和release 模式翻译成的汇编代码是不一样的,编译器会优化的。
- 我们可以调节这里的选项方便我们阅读
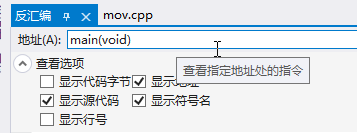
mov
含义
mov指令用于将一个值写入某个寄存器
mov dest src
dest:目标 src:移动的值
翻译过来 把 src 的数据存到dest 里面类似为 dest=src
实例
a=425;
我们看一下 int a=425; 的汇编语言

mov EAX dword prt [a],1A9h
强调3点的是:
- 我们为了方便表示,汇编的数据几乎不直接使用二进制表示,
- 我们都是使用16进制(HEX)的,以及**方括号[]**里的东西都是地址
- word为一个字也就是两个字节,dword 就是double word 也就是 4字节,qword 就是4个字也就是8字节
像这里 的 dword prt [a] 意思是从&a的地方取两个字的大小的数据
当然这里的a是编译器帮我替换的,实际a应该是一串16进制的地址,我们去掉符号看一下

这里[ebp-8]的问题有点复杂,涉及的问题有点多,在后面我们在了解,现在来说其实就是:
cpu从寄存器ebp中取出数据-8得到了a的地址,然后把数据1A9存到改地址中
b=a;
其实这是两句汇编
004C203F mov eax,dword ptr [ebp-8]
004C2042 mov dword ptr [ebp-14h],eax

直白的说就是,先把a的值给eax 再把eax 值赋值到 b的地址里面
补充 为什么要 dword ptr?
其实这个要回忆一下当时学c语言的时候 int 类型是4个字节(当前环境是如此),一个地址对应1个字节,我们在存int数据的时候,一个字节是放不下的,那么我们就需要从这个a的地址往下在扩展4个内存来存int的数据。
就以这个a=425;为例子
- 假设 a的地址为1001,那么1001到1004都是来存a的int数据的
- 425的16进制为1A9,那么在内存的情况应该为
00 00 01 A9
大小端模式
其实这里我们遇到了一个问题 在内存的情况是这样呢?
- 情况1
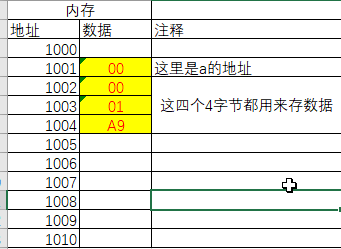
- 情况2
还是这样?
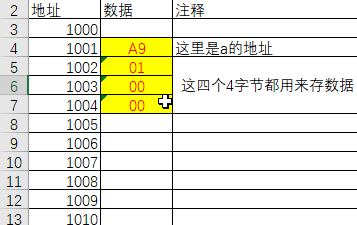
这样的问题就是大小端问题
大端模式
是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,显然情况2是大端模式
小段模式
是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
很显然,情况2是小端模式
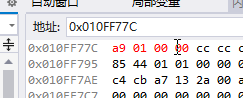
显然,我们现在的环境是 小端模式
什么决定着大小端模式
Intel的80x86系列芯片是唯一还在坚持使用小端的芯片,++ARM芯片默认采用小端,但可以切换为大端;++而MIPS等芯片要么采用全部大端的方式储存,要么提供选项支持大端——可以在大小端之间切换。另外,对于大小端的处理也和编译器的实现有关,在C语言中,默认是小端(但在一些对于单片机的实现中却是基于大端,比如Keil 51C),Java是平台无关的,默认是大端。在网络上传输数据普遍采用的都是大端。
---- 百度百科
lea 装在有效的地址值
lea dest,[地址值]
这个指令和mov很相似,但是这个专门针地址的,是把地址给dest,而mov 是吧地址里面的值给dest
结语
没有结语就是最好的结语


